Application Driven Data Synchronization between Databases
February 21, 2025
Introduction
In many applications, it can be advantageous to work with multiple databases. For example,
reporting, analytics, or even migrating data between systems may require a multi-database setup. One
common scenario - illustrated in this blog - is when advanced search capabilities are needed. In
such
cases, the primary business operations run on a relational database like PostgreSQL, while a
Lucene-based system such as OpenSearch is used to power sophisticated search features like full-text
search and relevance ranking.
However, using two databases introduces a new challenge: keeping the data synchronized between them.
In our example, PostgreSQL is the primary database, and any write is asynchronously replicated to
OpenSearch - making OpenSearch eventually consistent with PostgreSQL. The frequency of
synchronization - and the acceptable delay
before both
systems become consistent - depends on the application’s requirements. Some applications may only
need
a nightly sync, while others require near-instant replication, which makes the synchronization
process more demanding.
A common method to address this challenge is Change Data Capture (CDC). CDC is a technique that
detects and tracks incremental changes (inserts, updates, and deletes) in a database and treats
these changes as event streams for asynchronous processing. There are various ways to implement CDC,
each with its own complexities and infrastructure needs.
In certain cases, however, handling synchronization at the application layer might be a better
choice. By managing data replication within the application, you can avoid the overhead of setting
up specialized CDC infrastructure - such as connectors, message brokers, or log-parsing tools - and
incorporate complex data manipulation tasks before indexing in OpenSearch. This approach is
particularly attractive when you only need to sync data from one or two tables, and you wish to keep
your technology stack simple while maintaining robust, timely synchronization.
This blog post will focus on implementing application-driven synchronization in a Spring Boot Java
application. We will discuss strategies for handling potential data inconsistencies and provide a
practical example that minimizes complexity while ensuring fast and reliable data replication
between PostgreSQL and OpenSearch.
When and how to sync to OpenSearch?
When deciding when and how to sync data to OpenSearch, you might initially consider using JPA entity
lifecycle events - such as @PostPersist, @PostUpdate and
@PostRemove -
to trigger the
synchronization
directly. However, this approach is problematic because these events can be fired not only after a
transaction commits but also after a flush, which does not guarantee a committed state. If the
transaction later rolls back, you’d need to detect that and reverse the change in OpenSearch, which
can quickly become very complex.
To ensure that synchronization to OpenSearch only occurs after a successful transaction commit, it
is best to employ the Transactional Outbox Pattern. In this pattern, during a business transaction
that writes to PostgreSQL, an additional record is inserted into an outbox table to capture the
event. A separate process then consumes these events and performs the corresponding update in
OpenSearch. This ensures that even if the application crashes immediately after commit,
events can be retried on restart.
In our Spring Boot application, we can leverage Spring Modulith’s event-handling support. When
saving an entity that needs to be replicated, we publish an event via Spring’s
ApplicationEventPublisher. With Spring Modulith’s JPA integration, this event is
recorded in an
event publication table within the same transaction. Once the transaction commits, the event
listener is invoked to update OpenSearch. To handle cases where the application crashes after
commit, setting the property spring.modulith.republish-outstanding-events-on-restart
to true (or using the
IncompleteEventPublications interface) ensures that any pending events are retried.
Note that
marking an event as complete happens in a separate transaction, which can lead to the same event
being processed more than once, following the "at least once" semantics. Consequently, it is
important to design your OpenSearch write operations to be idempotent.
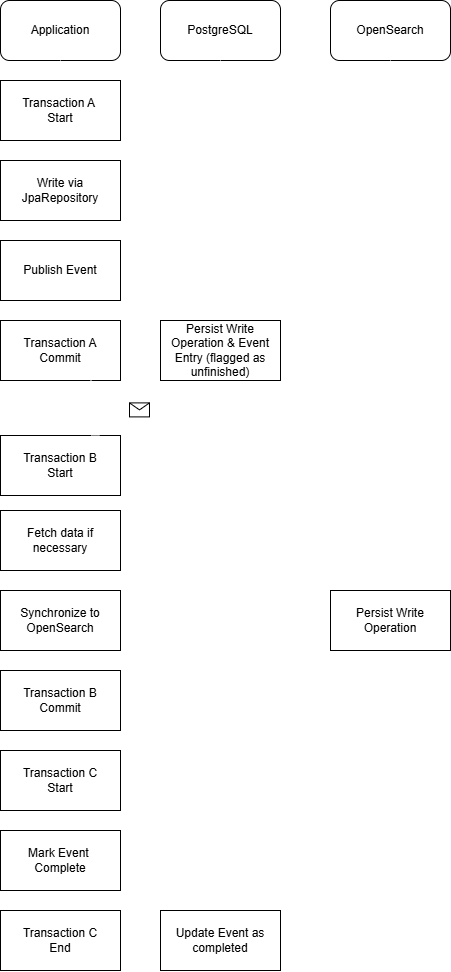
Sending Replication Events
The Java service class below illustrates how to save an entity and publish a corresponding event
within a transactional method, making also use of Spring Modulith’s event publication
registry.
In
this design, the event is published only after the transaction
successfully commits; if the transaction is rolled back, no event is emitted. Additionally, in
the
background but within the transaction, an entry is inserted into the
event_publication
table to track the event.
@Service @RequiredArgsConstructor public class EntityNameService { private final EntityNameRepository entityNameRepository; private final ApplicationEventPublisher publisher; @Transactional public void save(EntityName entity) { EntityName savedEntity = entityNameRepository.save(entity); publisher.publishEvent( SaveEntityNameEvent.builder() .entityId(savedEntity.getId()) .build() ); return savedEntity; } }
Although this approach ensures that events are only published after a successful transaction
commit,
replicating explicit event publication in every service class that performs write operations can
become both cumbersome and error-prone. Developers must remember to invoke event publication
after
each write operation, which introduces the risk of inconsistencies if an event is accidentally
omitted.
To address this, we can apply the Delegate Pattern to encapsulate event publication within the
repository layer itself. This allows services to continue using a standard repository interface
without needing to be aware of event handling. By wrapping the default JPA repository with a
custom
implementation, we can inject additional behavior - such as event publishing - without modifying
business logic in service classes. This abstraction keeps event management centralized,
improving
maintainability and reducing duplication.
The implementation below demonstrates this approach.
Initially, we define a standard JPA repository that provides default methods such as
save and saveAll:
@Repository public interface EntityNameRepository extends JpaRepository<EntityName, Long> { }
Since the intention is not to use Spring’s default implementation of the repository but rather a
custom one, a custom class implementing this interface is created. To ensure that this
implementation is selected over the default, it is annotated with @Primary. In this
custom implementation, the Spring Data JPA repository is injected as a delegate alongside the
ApplicationEventPublisher for event handling. When implementing the interface
methods,
the operation is first delegated to the JPA repository, and then an appropriate event is
published
by passing the affected entity identifier(s).
@Primary @Repository @RequiredArgsConstructor public class ReplicatingEntityNameRepository implements EntityNameRepository { private final EntityNameRepository delegate; private final ApplicationEventPublisher publisher; @Override @Transactional public <S extends EntityName> S save(S entity) { S savedEntity = delegate.save(entity); publisher.publishEvent( SaveEntityNameEvent.builder() .entityId(savedEntity.getId()) .build() ); return savedEntity; } // Other methods ... }
One potential issue with this approach arises when using cascading write operations in JPA.
Handling
cascading operations in JPA can be challenging because tracking changes across related entities
is
inherently complex. For example, if a parent entity is configured to cascade persistence
operations
to its child entities (using configurations such as CascadeType.PERSIST or
CascadeType.MERGE), the custom repository - designed to intercept explicit
save calls - does not automatically trigger event publication for these cascaded
operations. In general, cascading introduces an additional layer of complexity, and you would
need
to implement extra checks within your repository to ensure that all related entities trigger the
appropriate event synchronization.
Event Consumption
When handeling the consumption of such an event, it is crucial to carefully consider all possible edge cases and potential issues. If not handled correctly, the databases could fall out of sync, possibly without the developer's awareness. The following example illustrates a naive approach that fails to address these complexities:
@ApplicationModuleListener public void on(SaveEntityNameEvent event) { jpaRepository.findById(event.getEntityId()) .ifPresent(entity -> openSearchRepository.save(entity)); }
Let's begin by
examining the key requirements for performing a write operation to OpenSearch via the OpenSearch
repository. Ensuring that write operations to OpenSearch are idempotent is necessary as stated
earlier. This can be
achieved by using the same identifier in both OpenSearch and the PostgreSQL entity, and by utilizing
idempotent HTTP methods like PUT /index/_doc/{id} or
DELETE /index/_doc/{id} when interacting with OpenSearch. The PUT
operation is inherently idempotent because OpenSearch processes it as an upsert - either inserting
the
data if the document with a given ID doesn't exist, or updating the existing document if it already
does. Caution should be exercised with partial updates, as they might not be idempotent in all
scenarios.
In addition to the need for idempotent operations, several design challenges
must be addressed. For example, consider situations where the OpenSearch save call fails, or the JPA
database operation encounters problems such as database inaccessibility. In the current design,
exceptions arising in these cases are not handled, potentially leading to inconsistent states. To
reduce these risks, it is recommended to implement a retry mechanism, such as via the
RetryTemplate provided by Spring, and to wrap the entire method in a try-catch block to
manage situations where retry limits are reached. In the event of failure after retries, proper
notification should be sent to the developer - whether through error logs, metric alerts, or other
predefined notification channels based on the application’s alerting strategy.
Further
considerations arise when the application crashes during the transaction process. In such cases,
replication to OpenSearch will also fail. After the application is restarted, the event will be
reprocessed automatically, but only if the
spring.modulith.republish-outstanding-events-on-restart configuration is set to true
(or custom code that handles reprocessing on startup is implemented). An adjusted method would look
like this:
@ApplicationModuleListener public void on(SaveEntityNameEvent event) { try { Optional<EntityName> entity = retryTemplate.execute(context -> jpaRepository.findById(event.getEntityId()) ); entity.ifPresent(e -> retryTemplate.execute(context -> { openSearchClient.index(indexRequest(e)); return null; }); ); } catch (Exception e) { // Add alert or similiar, data stores are out of sync. } }
With these precautions, connection failures are effectively managed. However, race conditions remain a potential issue, where the order of operations in PostgreSQL might differ from the order in which events are consumed. This can lead to several scenarios:
- Concurrent Updates:
When two updates occur concurrently on the same entity in PostgreSQL, the transaction that
completes last will overwrite the previous changes if no locking mechanism is in place.
Consequently, two events are dispatched, and it is possible for one update to prevail over the
other when persisting data to OpenSearch, leading to inconsistencies between the two data
stores. Note that simply fetching the entity from the JPA repository during event consumption
does not guarantee an atomic save. If a new transaction commits after the data is fetched but
before the update to OpenSearch is completed, the older data might be written, causing a sync
issue. One solution is to enforce strict sequential processing of events - for example, using a
FIFO queue - though this can reduce throughput. Alternatively, implementing database locking
mechanisms, such as optimistic locking via a version attribute (using Spring’s
@Versionsupport), can prevent concurrent update conflicts by causing the later update to fail if it attempts to modify stale data. - Update Before Insert: In theory, an update event could be processed before the document is inserted into OpenSearch. This scenario is generally not problematic because OpenSearch’s upsert operation will insert the document if it does not exist, or update it if it does.
- Delete Before Insert/Update: There is also the possibility that a delete operation is processed before an insert or update operation. In the deletion case, the event consumer directly issues a delete command to OpenSearch using the provided identifier, without fetching data from PostgreSQL. If an insert or update occurs later, the subsequent data fetch from PostgreSQL ensures that no incorrect reinsertion happens. However, if your events carry the full data payload rather than just identifiers, additional measures might be necessary. One approach is to implement soft deletion, where records are not physically removed but are marked as deleted via a flag. In this case, delete operations become update operations that set the deletion flag, thereby avoiding synchronization issues.
Addressing these challenges is essential for creating a robust and reliable replication process. It is important to note that the current solution assumes a single-instance application; additional considerations may be required in a replicated environment.
Handeling Replication
In a distributed system, it can be advantageous to use an external message queue to offload event dissemination. This approach ensures that data updates are reliably transmitted even when multiple instances are saving data simultaneously. Spring Modulith facilitates this by enabling the publication of events to a variety of message brokers - such as Kafka, AMQP, or SQS - using built-in abstractions. However, because sending an event now involves a network call rather than an in-memory operation, additional challenges arise. If the call to the broker fails, robust error handling and retry mechanisms must be implemented to guarantee eventual delivery of the event. On the consumption side, the built-in idempotency and at-least-once delivery semantics help ensure reliable processing. In cases where errors persist, integrating constructs like dead-letter queues will further safeguard the system by capturing and managing problematic messages.
Conclusion
With this solution, synchronization becomes robust without the need to resort to CDC techniques - resulting in a clean and maintainable implementation. The only scenario in which data might fall out of sync is if the retry mechanism for external systems ultimately fails. For these rare cases, it is advisable to have a manual synchronization job available. This job can identify discrepancies between databases - for instance, by comparing hashes - and then generate the necessary write operations to reconcile the differences, ensuring data consistency even under extended failure conditions.